就像Python的编码问题一样,网络协议问题也总是在工程的开展中犹如一个幽灵一样经常困扰着我。现在回想起来学习网工的时候关于TCP也只是了解即可,几乎没有让我操控的场景。直到接触到Socket网络编程以及TCP性能调优之后,才知道深度了解TCP协议的重要性。前两天看了一本书,书名为《Wireshark网络分析就这么简单》。虽然内容和书名严重不符,完全都不JB简单,就像这篇名为《闲聊TCP》的水贴也都是干货一样![]()
![]()
TCP基础
1.MTU:二层的最大传输大小,对IP包进行切分。默认为1500bytes。若IP包>1500则会拆分成IP header ID相同的分片。
MSS:传输层的最大传输大小,只包含TCP的载荷即上层应用,是对上层应用传输数据的限制。若MTU为1500,MSS则要减去IP头部和TCP头部的大小(如果IP和TCP Option均不启用,则MSS=1500-20-20=1460)。若应用数据超过MSS则会被拆分。
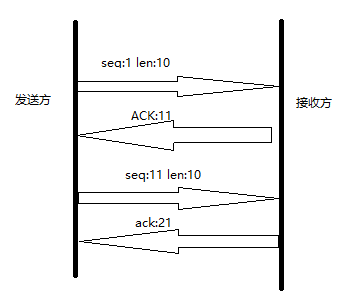
2. TCP提供有序的传输,每个数据段都有标号。当接收方收到乱序的包,可以根据序号重新排序。若分段1其实Seq为1,Lenth=1448,则分段2Seq=1+1448=1449。若分段2lenth也为1448,则分段3seq为1449+1448=2897。Seq=上一个Seq+lenth。
ACK:发送方的seq+len。例如发送方seq=x,len=y,则接收方ACK=x+y,意味着接收方收到了x+y前所有的bytes。
3.RST:用于重置一个混乱的连接或拒绝无效的请求。生产环境中若有RST包一般会有重大问题,需要引起重视。
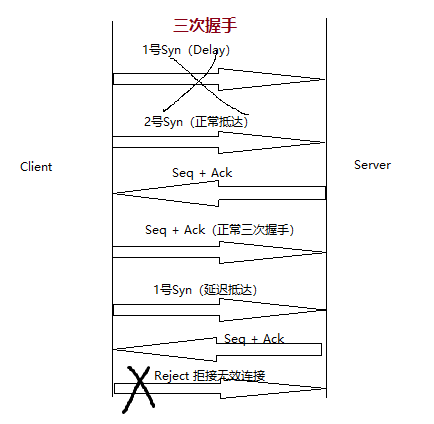
4.三次握手Seq并不是从0开始,只是wireshark启用了Relative Sequence Number所以显示为0。
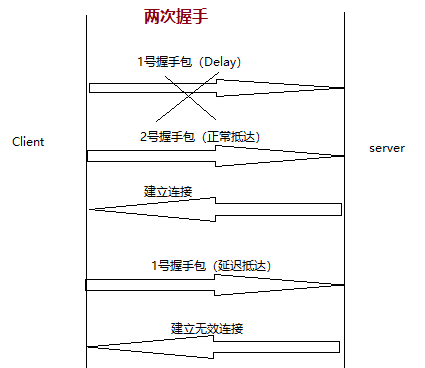
5.为什么用三次握手而不用两次握手:若两次握手,Client→Server发送第一个握手包如果Delay,再次发送第二个握手包没有Delay,Server与之建立连接,而后Server再次收到1号包也会用1号包和Client进行无效的连接。
TCP如何避免“堵车”
1.TCP分段中含有win=字段(windows size),这不是发送窗口,而是向对方声明自己的接收窗口,对方收到后会把自己的发送窗口限制在这个数值,也称为滑动窗口机制。
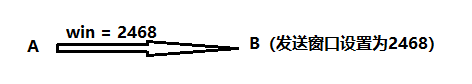
发送窗口决定一次发送的数据,MSS决定拆分为多少份。
2.TCP的接受窗口被设计为16bit,最大只能支持65535bytes,在当今网络环境成为了瓶颈,于是有了window scale机制,是TCP的Option。在TCP进行三次握手连接的时候声明一个shift count来扩展接受窗口。具体计算方式为 接收窗口 = win * (2^shiftcount)。
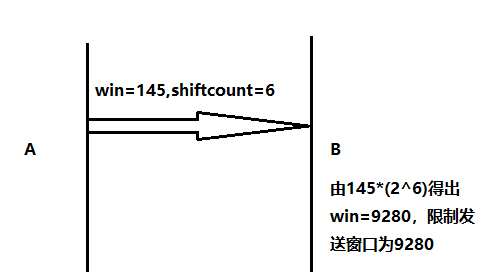
wireshark已经根据三次握手的shift count得出winsize。若抓包时win值很小,可能是由于Policy阻挡shiftcount协商过程,非常影响性能。
3.网络发生拥塞会产生丢包这种现象,即使在不对等链路带宽(一端100M一端1000M)可以由自动协商机制按照100M运行也没意义。因为带宽为多个连接所共享,连接之间无法协商状态,会有资源抢占的现象,因此要限制窗口。
TCP的策略是在发送方维护一个虚拟拥塞窗口,并利用各种算法趋于真实的拥塞点。对发送窗口的限制就是通过这个拥塞窗口来实现。
具体机制为:
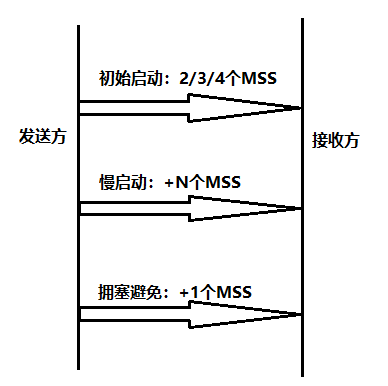
a.初始启动:发送方刚连接时候对网络状况一无所知,先把拥塞窗口设置很小。RFC建议为2/3或4个MSS,具体视MSS大小而定。
b.慢启动阶段:若全被应答,则继续提升窗口大小。由于这个阶段拥塞概率低,因此增速快。RFC建议每收到N个确认,可以加N个MSS。比如发送2接受2,下一次2+2=4,在下次4+4=8….这个过程增速快但是基数小,启动慢,因此叫慢启动。
c.拥塞避免阶段:慢启动到一个较大的值,触碰拥塞点概率大,不再慢启动。RFC建议每个往返加一个MSS。比如发了16个MSS全部被确认,下一次增加到16+1=17个。这个过程称为拥塞避免,若之前已经发生拥塞,则该点就作为参考。
4.为什么平时很少感到拥塞?
a.OS若不启用window scale option,最大窗口只有64k。
b.同步传输要求窗口小(NFS同步模式)。
c.时间短,难以感知。
东西送丢了可咋整
1.从发出原始包到重传该包的时间称为RTO。期间无法传输数据。
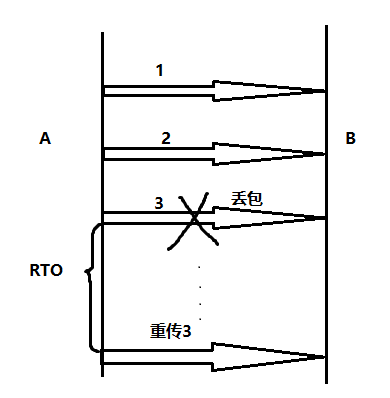
2.快速重传机制:若网络中轻微丢包或Checksum错误,接收方接到的后续包收到之后发现Seq比预期大,于是发ACK提醒期望的Seq,让发送方重传。当发送方收到大于等于3个DupACK会立刻重传,这个过程称为快速重传,不用等待RTO这段空白时间。
3.快速重传机制下由于发送方不知道丢了几个包,于是最初的TCP只能重传丢的包以及后续所有的数据包,效率低下,于是有了以下两种方案:
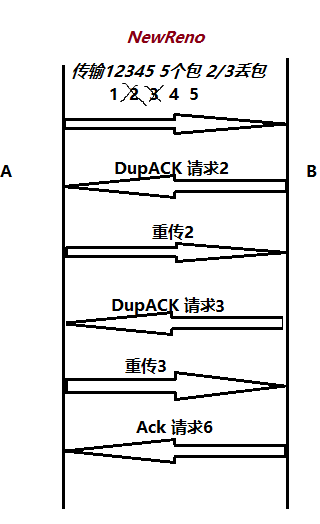
NewReno:丢包后接收端先发送丢的第一个包的ACK给发送端,再发送第二个丢的包的ACK,以此类推直到发送方发送所有重传包,接收端再发送新包的ACK请求。丢包多的时候会消耗更多的RTT(往返时间)。
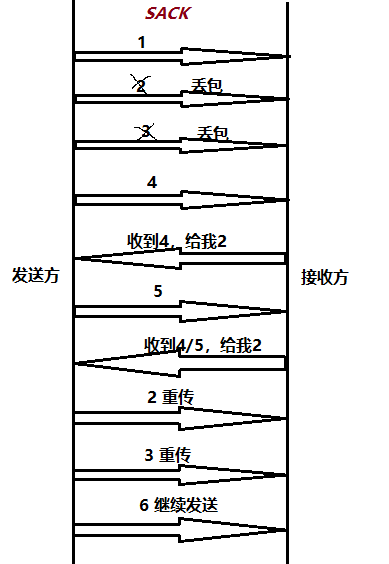
SACK:接收端若发现丢包,则向发送方请求丢的包的时候带上已经接受到的包,避免了发送方重传重复的包。
性能相关
1.延迟确认机制:接收方若收到一个包之后暂时没有数据发送,则延迟一段时间(windows默认200ms)再进行确认,若期间有数据可以合并在一起发送。
2.UDP不一定比TCP性能好,比如NFS在TCP场景下由TCP重传丢包(DupACK机制),而UDP要由应用来全部重传。
阿满大神的一些总结
1.如果没有拥塞,发送窗口越大越好。
2.如果有拥塞,限制窗口可以提升性能,万分之一的重传对性能影响都很大。
3.超时重传性能影响最大,由于在RTO机制的空白期间无法传输数据,要避免。
4.快速重传对性能影响小,因为没有等待时间,窗口减小没有这么大。
5.SACK和NewReno有利于提高重传效率。
6.丢包对小文件影响比大文件大,因为小文件很难凑满DupACK,只能重传,而大文件会触发快速重传。
7.wireshark网络诊断三板斧:Summary、Service Response Time、Expert Info Composite
无关技术的RFC
最早的TCP和IP设计为一层,并不是两层。计算机科学家Jon Postel对此发文进行了批评,后来一年他的意见被采纳,TCP和IP分为两层设计,才有了如今的TCP/IP。Jon Postel是TCP/IP之父Vinton Cerf的高中同学,也是ARPA网的项目同事。1998年因病去世。Vinton也为他写了一篇感人的讣告作为RFC2468发布。
附上链接 https://www.rfc-editor.org/rfc/rfc2468.txt
TCP闲聊 Over…


